Excel中LINEST函数的语法与用法
本文介绍Microsoft Excel中LINEST函数的语法和用法。
函数说明
LINEST函数的主要作用是使用最小二乘法对已知数据进行最佳直线拟合,并返回描述此直线的数组。因为此函数返回数值数组,所以必须以数组公式的形式输入。
直线的公式为:
y = mx + b or
y = m1x1 + m2x2 + ... + b(如果有多个区域的 x 值)
式中,因变量 y 是自变量 x 的函数值。M 值是与每个 x 值相对应的系数,b 为常量。注意 y、x 和 m 可以是向量。LINEST 函数返回的数组为 {mn,mn-1,...,m1,b}。LINEST 函数还可返回附加回归统计值。
函数语法
LINEST(known_y's,known_x's,const,stats)
LINEST(Y,X,逻辑值,逻辑值)
参数说明
Known_y's:是关系表达式 y = mx + b 中已知的 y 值集合。
-
如果数组 known_y's 在单独一列中,则 known_x's 的每一列被视为一个独立的变量。
-
如果数组 known-y's 在单独一行中,则 known-x's 的每一行被视为一个独立的变量。
Known_x's:是关系表达式 y = mx + b 中已知的可选 x 值集合。
-
数组 known_x's 可以包含一组或多组变量。如果只用到一个变量,只要 known_y's 和 known_x's 维数相同,它们可以是任何形状的区域。如果用到多个变量,则 known_y's 必须为向量(即必须为一行或一列)。
-
如果省略 known_x's,则假设该数组为 {1,2,3,...},其大小与 known_y's 相同。
Const:为一逻辑值,用于指定是否将常量 b 强制设为 0。
-
如果 const 为 TRUE 或省略,b 将按正常计算。
-
如果 const 为 FALSE,b 将被设为 0,并同时调整 m 值使 y = mx。
Stats:为一逻辑值,指定是否返回附加回归统计值。
-
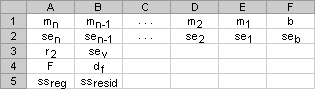
如果 stats 为 TRUE,则 LINEST 函数返回附加回归统计值,这时返回的数组为 {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey;F,df;ssreg,ssresid}。
-
如果 stats 为 FALSE 或省略,LINEST 函数只返回系数 m 和常量 b。
附加回归统计值如下:
| 统计值 | 说明 |
|---|---|
| se1,se2,...,sen | 系数 m1,m2,...,mn 的标准误差值。 |
| seb | 常量 b 的标准误差值(当 const 为 FALSE时,seb = #N/A) |
| r2 | 判定系数。Y 的估计值与实际值之比,范围在 0 到 1 之间。如果为 1,则样本有很好的相关性,Y 的估计值与实际值之间没有差别。如果判定系数为 0,则回归公式不能用来预测 Y 值。有关计算 r2 的方法的详细信息,请参阅本主题后面的“说明”。 |
| sey | Y 估计值的标准误差。 |
| F | F 统计或 F 观察值。使用 F 统计可以判断因变量和自变量之间是否偶尔发生过可观察到的关系。 |
| df | 自由度。用于在统计表上查找 F 临界值。所查得的值和 LINEST 函数返回的 F 统计值的比值可用来判断模型的置信度。有关如何计算 df,请参阅在此主题中后面的“说明”。示例 4 说明了 F 和 df 的使用。 |
| ssreg | 回归平方和。 |
| ssresid | 残差平方和。 有关计算 ssreg 和 ssresid 的方法的详细信息,请参阅本主题后面的“说明”。 |
下面的图示显示了附加回归统计值返回的顺序。
函数备注
-
可以使用斜率和 y 轴截距描述任何直线:
斜率 (m):
通常记为 m,如果需要计算斜率,则选取直线上的两点,(x1,y1) 和 (x2,y2);斜率等于 (y2 - y1)/(x2 - x1)。Y 轴截距 (b):
通常记为 b,直线的 y 轴的截距为直线通过 y 轴时与 y 轴交点的数值。直线的公式为 y = mx + b。如果知道了 m 和 b 的值,将 y 或 x 的值代入公式就可计算出直线上的任意一点。还可以使用 TREND 函数。
-
当只有一个自变量 x 时,可直接利用下面公式得到斜率和 y 轴截距值:
斜率:
=INDEX(LINEST(known_y's,known_x's),1)Y 轴截距:
=INDEX(LINEST(known_y's,known_x's),2) -
数据的离散程度决定了 LINEST 函数计算的精确度。数据越接近线性,LINEST 模型就越精确。LINEST 函数使用最小二乘法来判定最适合数据的模型。当只有一个自变量 x 时,m 和 b 是根据下面的公式计算出的:
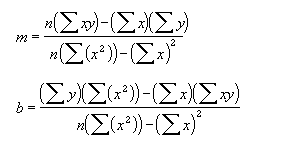
其中 x 和 y 是样本平均值,例如 x = AVERAGE(known x's) 和 y = AVERAGE(known_y's)。
-
直线和曲线函数 LINEST 和 LOGEST 可用来计算与给定数据拟合程度最高的直线或指数曲线。但需要判断两者中哪一个更适合数据。可以用函数 TREND(known_y's,known_x's) 来计算直线,或用函数 GROWTH(known_y's, known_x's) 来计算指数曲线。这些不带参数 new_x's 的函数可在实际数据点上根据直线或曲线来返回 y 的数组值,然后可以将预测值与实际值进行比较。还可以用图表方式来直观地比较二者。
-
回归分析时,Microsoft Excel 计算每一点的 y 的估计值和实际值的平方差。这些平方差之和称为残差平方和 (ssresid)。然后 Microsoft Excel 计算总平方和 (sstotal)。当 const = TRUE 或被删除时,总平方和是 y 的实际值和平均值的平方差之和。当 const = FALSE 时,总平方和是 y 的实际值的平方和(不需要从每个 y 值中减去平均值)。回归平方和 (ssreg) 可通过公式 ssreg = sstotal - ssresid 计算出来。残差平方和与总平方和的比值越小,判定系数 r2 的值就越大,r2 是表示回归分析公式的结果反映变量间关系的程度的标志。r2 等于 ssreg/sstotal。
-
在某些情况下,一个或多个 X 列可能没有出现在其他 X 列中的预测值(假设 Y's 和 X's 位于列中)。换句话说,删除一个或多个 X 列可能导致同样精度的 y 预测值。在这种情况下,这些多余的 X 列应该从回归模型中删除。这种现象被称为“共线”,原因是任何多余的 X 列被表示为多个非多余 X 列的和。LINEST 将检查是否存在共线,并在识别出来之后从回归模型中删除任何多余的 X 列。由于包含 0 系数以及 0 se's,所以已删除的 X 列能在 LINEST 输出中被识别出来。如果一个或多个多余的列被删除,则将影响 df,原因是 df 取决于被实际用于预测目的的 X 列的个数。有关计算 df 的详细信息,请参阅下面的示例 4。如果由于删除多余的 X 列而更改了 df,则也会影响 sey 和 F 的值。实际上,共线应该相对很少发生。但是,很可能引起共线的情况是,当某些 X 列仅包含 0's 和 1's 作为一个实验中的对象是否属于某个组的指示器。如果 const = TRUE 或被删除,则 LINEST 可有效地插入所有 1's 的其他 X 列以便模型化截取。如果有一列,1 对应于每个男性的对象,0 对应于非男性对象,还有一列,1 对应于每个女性对象,0 对应于非女性对象,那么后一列就是多余的,原因是其中的项可通过从所有 1's(由 LINEST 添加)的另一列中减去“男性指示器”列中的项来获得。
-
df 的计算方法,如下所示(没有 X 列由于共线而从模型中被删除):如果存在 known_x's 的 k 列和 const = TRUE 或被删除,那么 df = n – k – 1。如果 const = FALSE,那么 df = n - k。在这两种情况下,每次由于共线而删除一个 X 列都会使 df 加 1。
-
对于返回结果为数组的公式,必须以数组公式的形式输入。
-
当需要输入一个数组常量(如 known_x's)作为参数时,以逗号作为同一行中数据的分隔符,以分号作为不同行数据的分隔符。分隔符可能因“区域设置”中或“控制面板”的“区域选项”中区域设置的不同而有所不同。
-
注意,如果 y 的回归分析预测值超出了用来计算公式的 y 值的范围,它们可能是无效的。?
函数示例
示例1:斜率和 Y 轴截距
| 已知 y | 已知 x |
|---|---|
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| 公式 | 公式 |
| =LINEST(A2:A5,B2:B5,,FALSE) |
注释:示例中的公式必须以数组公式输入。在将公式复制到一张空白工作表后,选择以公式单元格开始的区域 A7:B7。按 F2,再按 Ctrl+Shift+Enter。如果公式不是以数组公式输入,则返回单个结果值 2。
当以数组输入时,将返回斜率 2 和 y 轴截距 1。
示例2:简单线性回归
| 月 | 销售 |
|---|---|
| 1 | 3100 |
| 2 | 4500 |
| 3 | 4400 |
| 4 | 5400 |
| 5 | 7500 |
| 6 | 8100 |
| 公式 | 说明(结果) |
| =SUM(LINEST(B2:B7, A2:A7)*{9,1}) | 估算第 9 个月的销售值 (11000) |
通常,SUM({m,b}*{x,1}) 等于 mx + b,即给定 x 值的 y 的估计值。也可以使用 TREND 函数。
示例3:多重线性回归
假设有开发商正在考虑购买商业区里的一组小型办公楼。
开发商可以根据下列变量,采用多重线性回归的方法来估算给定地区内的办公楼的价值。
?
| 变量 | 代表 |
|---|---|
| y | 办公楼的评估值 |
| x1 | 底层面积(平方英尺) |
| x2 | 办公室的个数 |
| x3 | 入口个数 |
| x4 | 办公楼的使用年数 |
本示例假设在自变量(x1、x2、x3 和 x4)和因变量 (y) 之间存在线性关系。其中 y 是办公楼的价值。
开发商从 1,500 个可选的办公楼里随机选择了 11 个办公楼作为样本,得到下列数据。“半个入口”指的是运输专用入口。
| 底层面积 (x1) | 办公室的个数 (x2) | 入口个数 (x3) | 办公楼的使用年数 (x4) | 办公楼的评估值 (y) |
|---|---|---|---|---|
| 2310 | 2 | 2 | 20 | 142,000 |
| 2333 | 2 | 2 | 12 | 144,000 |
| 2356 | 3 | 1.5 | 33 | 151,000 |
| 2379 | 3 | 2 | 43 | 150,000 |
| 2402 | 2 | 3 | 53 | 139,000 |
| 2425 | 4 | 2 | 23 | 169,000 |
| 2448 | 2 | 1.5 | 99 | 126,000 |
| 2471 | 2 | 2 | 34 | 142,900 |
| 2494 | 3 | 3 | 23 | 163,000 |
| 2517 | 4 | 4 | 55 | 169,000 |
| 2540 | 2 | 3 | 22 | 149,000 |
| 公式 | ||||
| =LINEST(E2:E12,A2:D12,TRUE,TRUE) |
注释:示例中的公式必须以数组公式输入。在将公式复制到一张空白工作表后,选择以公式单元格开始的区域 A14:E18。按 F2,再按 Ctrl+Shift+Enter。如果公式不是以数组公式输入,则返回单个结果值 -234.2371645。
当作为数组输入时,将返回下面的回归统计值,可用该值可识别所需的统计值。

多重回归公式,y = m1*x1 + m2*x2 + m3*x3 + m4*x4 + b,可通过第 14 行的值得到:
y = 27.64*x1 + 12,530*x2 + 2,553*x3 - 234.24*x4 + 52,318
现在,开发商用下面公式可得到办公楼的评估价值,其中面积为 2,500 平方英尺、3 个办公室、2 个入口,已使用 25 年:
y = 27.64*2500 + 12530*3 + 2553*2 - 234.24*25 + 52318 = $158,261
或者,可将下表复制到示例工作簿的单元格 A21。
| 底层面积 (x1) | 办公室的个数 (x2) | 入口个数 (x3) | 办公楼的使用年数 (x4) | 办公楼的评估值 (y) |
|---|---|---|---|---|
| 2500 | 3 | 2 | 25 | =D14*A22 + C14*B22 + B14*C22 + A14*D22 + E14 |
也可以用 TREND 函数计算此值。
示例4:使用 F 和 R2 统计
在上例中,判定系数(或 r2)为 0.99675(函数 LINEST 的输出单元格 A17 中的值),表明在自变量与销售价格之间存在很大的相关性。可以通过 F 统计来确定具有如此高的 r2 值的结果偶然发生的可能性。
假设事实上在变量间不存在相关性,但选用 11 个办公楼作为小样本进行统计分析却导致很强的相关性。术语“Alpha”表示得出这样的相关性结论错误的概率。
LINEST 输出中的 F 和 df 可被用于计算意外出现的较高 F 值的可能性。F 可与发布的 F 分布表中的值进行比较,或者 Excel 的 FDIST 可被用于计算意外出现的较高 F 值的概率。相应的 F 分布具有 v1 和 v2 自由度。如果 n 是数据点的个数,且 const = TRUE 或被删除,那么 v1 = n – df – 1 且 v2 = df。(如果 const = FALSE,那么 v1 = n – df 且 v2 = df。)Excel 的 FDIST(F,v1,v2) 将返回意外出现的较高 F 值的概率。在示例 4 中,df = 6 (cell B18) 且 F = 459.753674 (cell A18)。
假设存在 Alpha 值等于 0.05,v1 = 11 – 6 – 1 = 4 且 v2 = 6,那么 F 的临界值是 4.53。因为 F = 459.753674 远大于 4.53,所以意外出现高 F 值的可能性非常低。(如果 Alpha = 0.05,假设当 F 超过临界值 4.53 时,没有 known_y's 和 known_x's 之间的关系可被拒绝)使用 Excel 的 FDIST 可获得意外出现的较高 F 值的概率。FDIST(459.753674, 4, 6) = 1.37E-7,一个极小的概率。于是可以断定,无论通过在表中查找 F 的临界值,还是使用 Excel 的 FDIST,回归公式都可用于预测该区域中的办公楼的评估价值。请注意,使用在上一段中计算出的 v1 和 v2 的正确值是非常关键的。
示例5:计算 T 统计
另一个假设检验可以检验示例中的每个斜率系数是否可以用来估算示例 3 中的办公楼的评估价值。例如,如果要检验年数系数的统计显著水平,用 13.268(单元格 A15 里的年数系数的估算标准误差)去除 -234.24(年数斜率系数)。下面是 T 观察值:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
如果 t 的绝对值足够大,那么可以断定倾斜系数可用来估算示例 3 中的办公楼的评估价值。下表显示了 4 个 t 观察值的绝对值。
如果查阅统计手册里的表格,将会发现:双尾、自由度为 6、Alpha = 0.05 的 t 临界值为 2.447。该临界值还可使用 Excel 的 TINV 函数计算,TINV(0.05,6) = 2.447。既然 t 的绝对值为 17.7,大于 2.447,则年数对于估算办公楼的评估价值来说是一个显著变量。用同样方法,可以测试自变量的统计显著水平。下面是每个自变量的 t 观察值。
| 变量 | t 观察值 |
|---|---|
| 底层面积 | 5.1 |
| 办公室的个数 | 31.3 |
| 入口个数 | 4.8 |
| 使用年数 | 17.7 |
这些值的绝对值都大于 2.447;因此,回归公式的所有变量都可用来估算区域内的办公楼的评估价值。
……